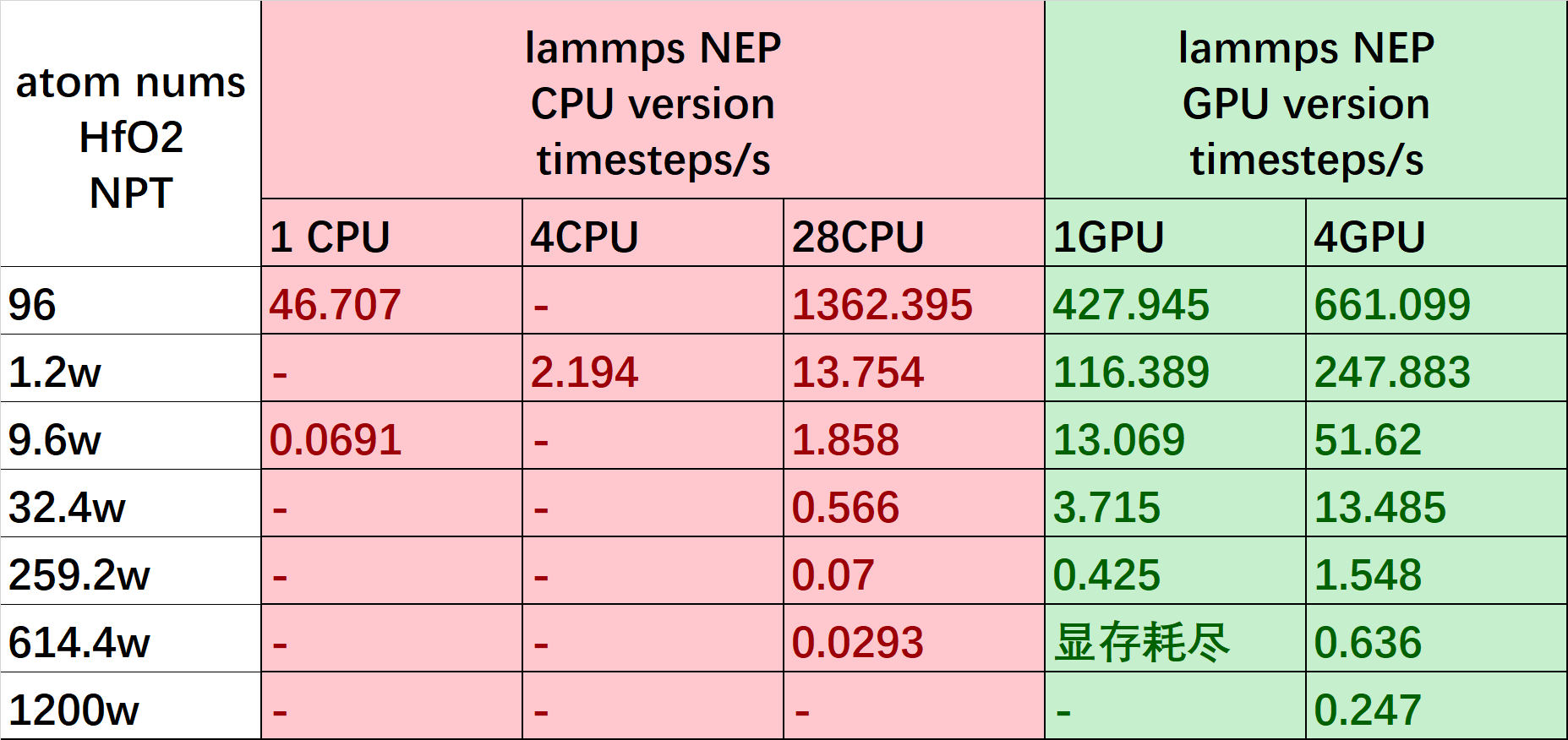
NEP Model
NEP模型最初是在GPUMD软件包中实现的 (2022b NEP4 GPUMD)。GPUMD 中训练 NEP 采用了可分离自然演化策略(separable natural evolution strategy,SNES),由于不依赖梯度信息,实现简单。但是对于标准的监督学习任务,特别是深度学习,更适合采用基于梯度的优�化算法。我们在 PWMLFF 2024.5 版本实现了 NEP 模型(NEP4,网络结构如图1所示),能够使用 PWMLFF 中基于梯度的LKF 或 ADAM 优化器做模型训练。
我们在多种体系中比较了LKF和SNES两种优化方法的训练效率,测试结果表明,LKF 优化器在对NEP模型的训练中展现了优越的训练精度和收敛速度 NEP模型的网络结构只有一个单隐藏层,具有非常快的推理速度,而引入LKF优化器则大幅提高了训练效率。用户可以在PWMLFF中以较低的训练代价获得优质的NEP并使用它进行高效的机器学习分子动力学模拟,这对于资源/预算有限的用户非常友好。
我们也实现了 NEP 模型的Lammps分子动力学接口,支持 CPU 或 GPU 设备,受益于NEP 简单的网络结构和化繁为简的feature设计,NEP 模型在 lammps 推理中具有非常快的速度。
NEP 网络结构,不同类型的元素具有独立但结构相同的子神经网络。此外,与文献中NEP4网络结构不同的是,对于每层的bias,所有的 子网络不共享最后一层bias。此外,我们对于多体描述符采用了与两体描述符相同的 cutoff。
NEP 命令列表
1.train 训练命令,与 DP、NN、Linear 模型相同,详细使用参考 NEP 模型训练
PWMLFF train train.json
2.python 测试接口我们提供了infer 和 test 两种命令,使用方式与 DP inference 相同。
对于 infer 命令,指定 nep 力场文件路径即可,这里支持来自 GPUMD 的 nep.txt 文件、 PWMLFF nep_model.ckpt 力场文件,以及在 lammps 中使用的 nep_to_lmps.txt 格式文件。
例如
PWMLFF infer nep_model.ckpt atom.config pwmat/config
PWMLFF infer gpumd_nep.txt 0.lammpstrj lammps/dump Hf O
# Hf O 为 lammps/dump格式的结构中的元素名称,Hf为结构中1号元素类型,O为元素中2号元素类型
在test命令的 test.json 中,同样支持上述力场格式。如果您测试的结构中原子数不超过万级,建议您使用 CPU 即可。对于 test 接口,我们使用了 cpu 多核并行加速。
PWMLFF test test.json
3.toneplmps 命令, 用于把 PWMLFF 训练的 nep_model.ckpt 文件转换为 nep_to_lmps.txt文件,用于 lammps 模拟。
PWMLFF toneplmps nep_model.ckpt
4.togpumd 命令,用于把PWMLFF 训练的nep_model.ckpt 文件转换为 nep_to_gpumd.txt 文件,可用于 GPUMD 模拟。
nep_to_lmps.txt 相比于 GPUMD 的 nep_to_gpumd.txt 区别是额外存储了不同元素各自的 last bias,因此,因此多了 行值, 为元素类型,如果只有单元素,那它们完全相同。
由于GPUMD 不同元素的网络共享最后一个 bias, 因此需要根据模拟体系做转换。我们这里的转换思路如下公式所示。
这里 为元素类型数量, 为力场中元素类型 对应的 bias , 为待模拟体系中类型为 的元素对应的原子数量。
# 您可以输入如下命令,查询输入参数详解
PWMLFF togpumd -h
#完整的转换参数例子如下所示,这里以HfO2体系为例,假设您要模拟一个Hf原子数目为N, O 原子数目为 M 的体系
#命令执行后您将得到一个nep_to_gpumd.txt 力场文件,可以用于GPUMD中模拟
#注意,这种方式只适用于体系中不同类型原子的数量不改变的 MD 模拟
PWMLFF togpumd -m nep_model.ckpt -t Hf O -n N M
5.topwmlff 命令,用于把文本格式的 nep.txt 力场文件转换为PWMLFF Pytorch 格式力场文件,命令完成后,您会得到一个名为 nep_from_gpumd.ckpt的 pytorch 格式力场文件。
PWMLFF topwmlff nep.txt nep.in
NEP 模型训练
我们这里以一个HfO2的数据集为例,例子位于 [源码/example/HfO2].
输入文件设置
训练 NEP 模型的输入文件与 Linear\NN\DP 模型输入类似。
需要准备一个输入控制 json 文件,最简单的输入设置如下所示,指定模型类型为NEP,原子类型顺序以及用于训练的 MOVEMENT 文件列表或者 pwdata 数据格式。将采用 LKF 优化器训练。这里以pwdata格式数据集为例。
{
"model_type": "NEP",
"atom_type": [8, 72],
"max_neigh_num": 100,
"datasets_path": [
"./pwdata/init_000_50/",
"...."
]
}
如果您需要使用MOVEMENT格式,那么请使用如下输入设置:
{
"model_type": "NEP",
"atom_type": [8, 72],
"raw_files": [
"./mvm_19_300/MOVEMENT",
"..."
]
}
这里建议您将数据转换为pwdata格式之后再做训练。 您可以使用 pwdata转换工具,也可以使用 pwact 主动学习中提供的 to_pwdata 转换命令,如下所示。
# pwact 转换MOVEMENT 为 pwdata 格式命令
pwact to_pwdata -i mvm_init_000_50 mvm_init_001_50 mvm_init_002_50 -s pwdata -f pwmat/movement -r -m -o 0.8
# -i 结构文件列表
# -f 结构文件格式 支持pwmat/movement 或 vasp/outcar
# -s 保存的目录名称
# -r 指定将数据做乱序保存
# -m 指定合并转换后的数据,如果您的MOVMENT 文件列表元素种类相同和原子数量相同,您可以使用该参数,将训练集作为一个文件夹保存
# -o 指定训练集和测试集划分比例,默认为0.8
如果您的conda环境未安装 pwact,请使用如下命令在线安装,或者参考 pwact 手册。
pip install pwact
NEP 配置参数详解
关于 NEP 的参数解释,请参考 NEP 参数手册
训练
训练 NEP 模型,用户只需要在当前 train.json 所在目录执行如下命令即可。以 [源码/example/HfO2] 为例。
cd /example/HfO2
PWMLFF train train.json
# 如果您执行 sbatch train.job ,这里job文件中的环境变量需要修改为您自己的环境变量,我们提供了在mcloud上的加载以及离线安装的加载slurm脚本例子。
训练完成后的输出文件
训练完成后,会在当前目录下生一个 model_record 目录,包含如下 4 个文件:
nep_to_lmps.txt、nep_model.ckpt、epoch_valid.dat、epoch_train.dat
nep_model.ckpt为训练结束后的PWMLFF格式力场文件,nep_to_lmps.txt为该力场文件的 lammps 版本
epoch_valid.dat、epoch_train.dat 为训练过程中的 loss 记录文件
Python inference
使用方式与 DP 中的 Python inference 完全相同,您只需要修改力场文件为 NEP 力场文件即可。
NEP for Lammps
我们提供了 NEP 的 Lammps 接口,支持 CPU(单核或多核)、GPU(单卡或多卡)下的模拟。 您可以参考 lammps 目录下的 examples/nep_lmps/hfo2_lmps_96atoms 案例。此外,我们的 Lammps 接口也支持从 GPUMD 训练的 NEP4 模型,使用方式与PWMLFF中相同。
输入文件设置
将训练完成后生成的nep_model.ckpt力场文件用于 lammps 模拟,您需要:
step1 提取力场文件,您只需要输入如下命令
PWMLFF toneplmps nep_model.ckpt
转换成功之后,您将得到一个力场文件nep_to_lmps.txt。如果您的模型正常训练结束,在nep_model.ckpt同级目录下会存在一个已经转换的 nep_to_lmps.txt 文件,您可以直接用于lammps。
step2 lammps 输入文件设置
nep 的lammps 接口使用方式与 DP lammps 接口 完全相同,您只需要替换力场为 nep 力场即可,lammps 的输入文件示例如下:
pair_style pwmlff 1 nep_to_lmps.txt
pair_coeff * * 8 72
为了更灵活的使用,我们允许您的力场中的原子类型顺序与lammps的输入结构类型顺序不同。为此,您需要在 pair_coeff 这里指定模拟结构中的原子类型对应的原子序号。例如,如果您的结构中 1 为 O 元素,2 为 Hf 元素,您设置 pair_coeff * * 8 72即可。
您也可以将 nep_to_lmps.txt 文件替换为您的 GPUMD 的 NEP4、NEP5 力场文件。
step3 启动lammps模拟
如果您需要使用 CPU 设备做lammps 模拟,请输入如下指令,这里 64 为您需要使用的 CPU 核数,请根据自己的设备设置。
mpirun -np 64 lmp_mpi -in in.lammps
我们也提供了GPU 版本的 lammps接口,请输入如下指令。
mpirun -np 4 lmp_mpi_gpu -in in.lammps
这里 4 为需要使用的 CPU 核数。我们会根据使用的 GPU 数量(例如 4 个),将 线程平均分配到这 4 个 GPU 上做计算。我们建议您使用的 CPU 核数与您设置的 GPU 数量相同,多个线程在单个 GPU 上会由于资源竞争导致运行速度降低。
关于lammps环境变量
为了运行lammps,您需要导入如下环境变量,包括您的PWMLFF 路径以及lammps 路径
# 导入 cuda
module load cuda/11.8 intel/2020
# 导入您的conda 环境变量
source /the/path/anaconda3/etc/profile.d/conda.sh
conda activate torch2_feat
# 导入您的PWMLFF 环境变量
export PATH=/the/path/codespace/PWMLFF_nep/src/bin:$PATH
export PYTHONPATH=/the/path/codespace/PWMLFF_nep/src/:$PYTHONPATH
# 导入您的lammps 环境变量
export PATH=/the/path/codespace/lammps_nep/src:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$(python3 -c "import torch; print(torch.__path__[0])")/lib:$(dirname $(dirname $(which python3)))/lib:$(dirname $(dirname $(which PWMLFF)))/op/build/lib
关于NEP 模型的测试结果
LKF优化器更适用于NEP模型
我们对多种体系进行了测试,所有测试中将数据集的80%作为训练集,20%作为验证集。我们在公开的HfO2训练集(包含𝑃21/c、Pbca、𝑃ca21和𝑃42/nmc相的2200个结构)上对NEP模型分别在LKF和演化算法(SNES, GPUMD)训练,它们在验证集上的误差下降如下图2中所示。随着训练epoch增加,基于LKF的NEP模型相比于SNES,可以更快收敛到更低误差(误差越低精度越高)。在铝的体系下(包括3984个结构)也有相似结果(图3)。此外,我们在LiGePS体系以及五元合金体系中也有类似结果,更详细数据请参考已上传的训练和测试数据。
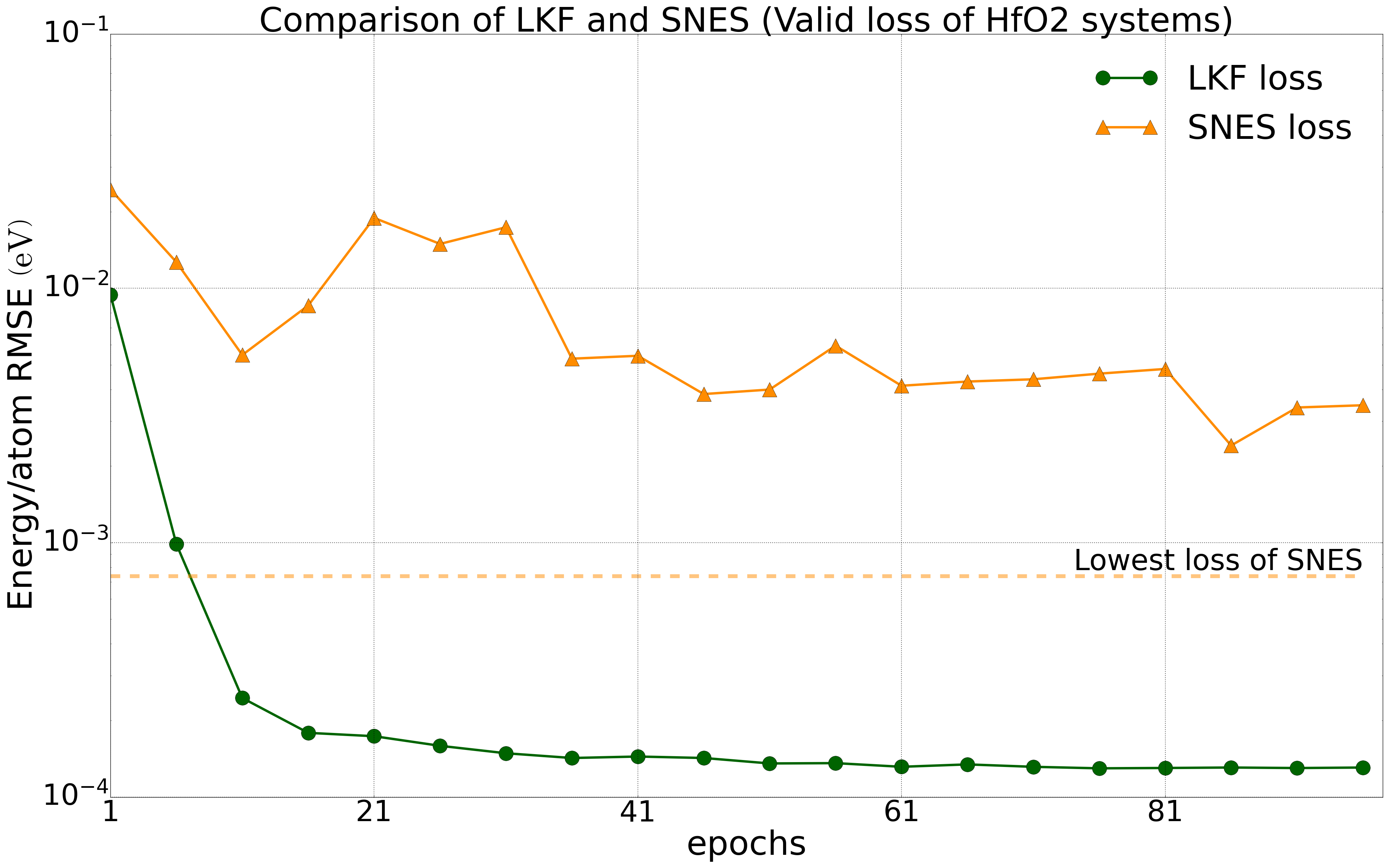
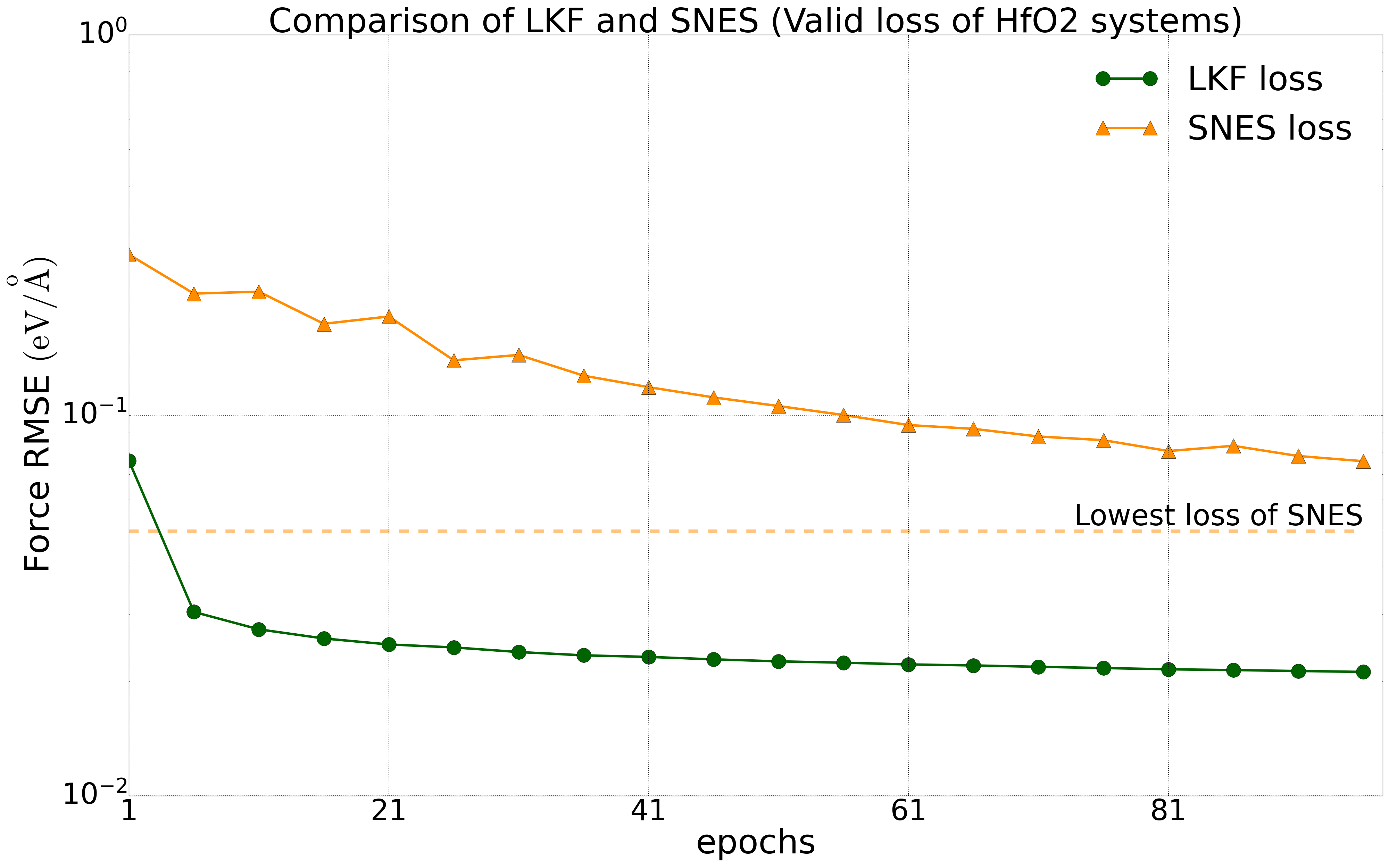
HfO2体系(2200个结构)下,NEP模型在LKF和SNES优化器下的能量(左图)和力(右图)收敛情况。图中虚线为SNES算法训练能够达到的最低loss水平。
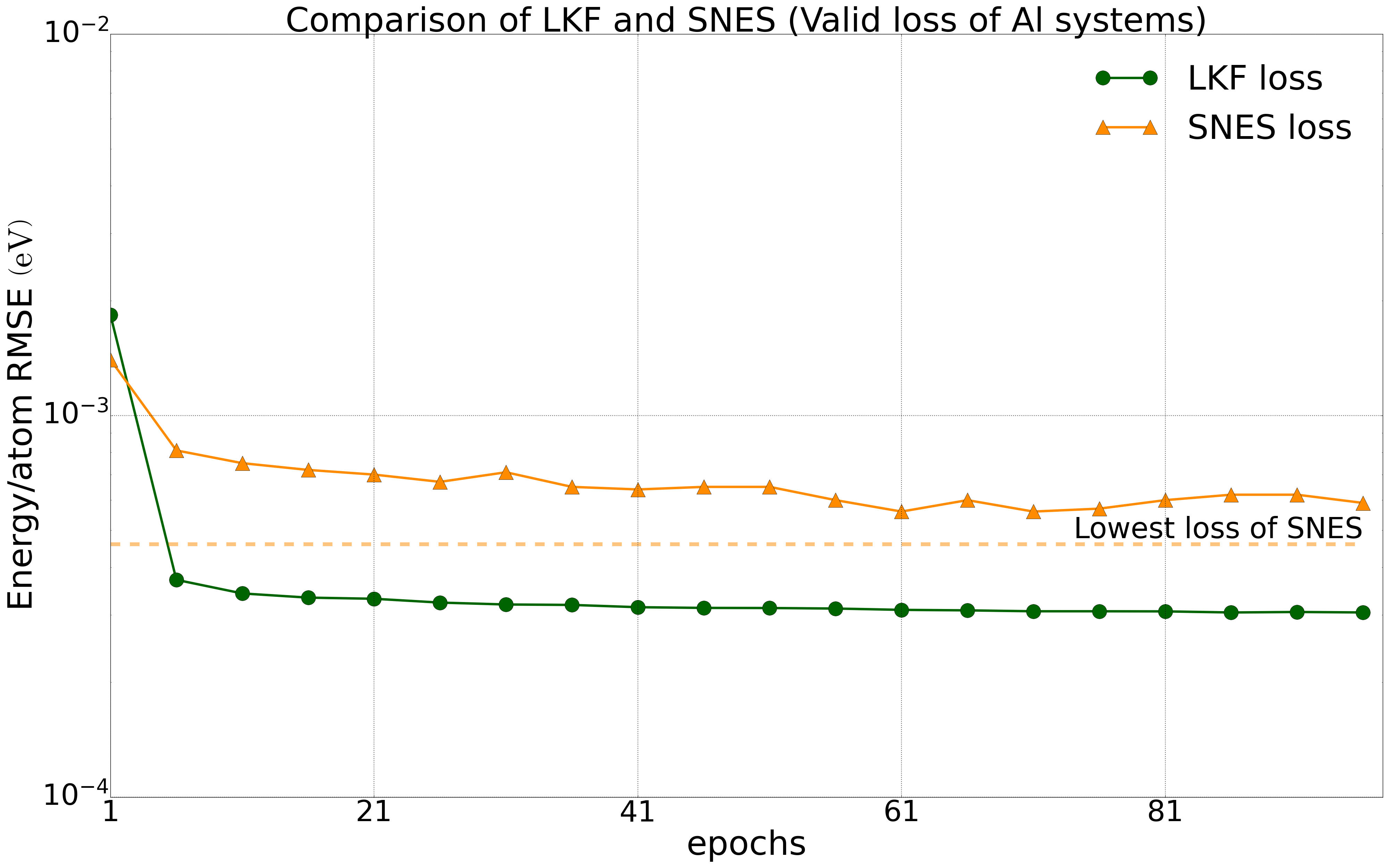
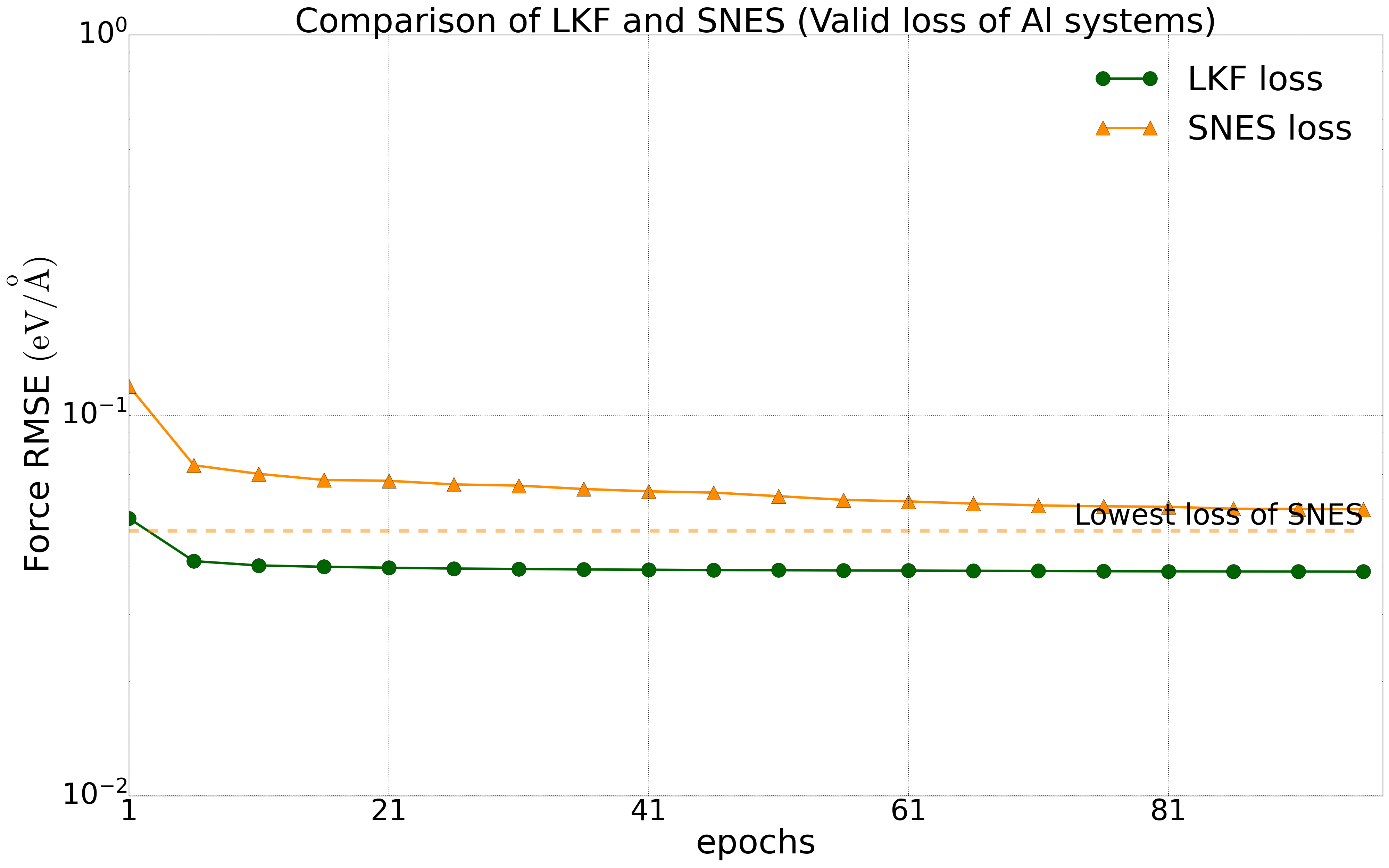
Al体系(3984个结构)下,NEP模型在LKF和SNES优化器下的能量(左图)和力(右图)收敛情况。图中虚线为SNES算法训练能够达到的最低loss水平。
PWMLFF中NEP模型与深度势能模型的精度对比
深度势能(deep potential, DP)模型是目前广泛使用的一种神经网络模型,PWMLFF中实现了Pytorch版本的DP模型,该DP模型也可以使用LKF优化器。我们在多个体系下,使用LKF优化器对NEP模型和DP(PWMLFF)模型训练做了对比,结果如下图4中所示。在Al、HfO2、LiGePS(包含1万个结构)、[Ru、Rh��、Ir、Pd、Ni]五元合金体系(包含9486个结构)下,PWMLFF中的NEP模型比DP模型收敛都更快,精度也更高。特别的,对于五元合金,我们采用type embedding DP以减少元素种类对训练速度的影响(在之前的测试中,我们发现,对五种以上的元素的情况,在PWMLFF的DP训练中引入type embedding可以获得比普通DP更高的精度)。
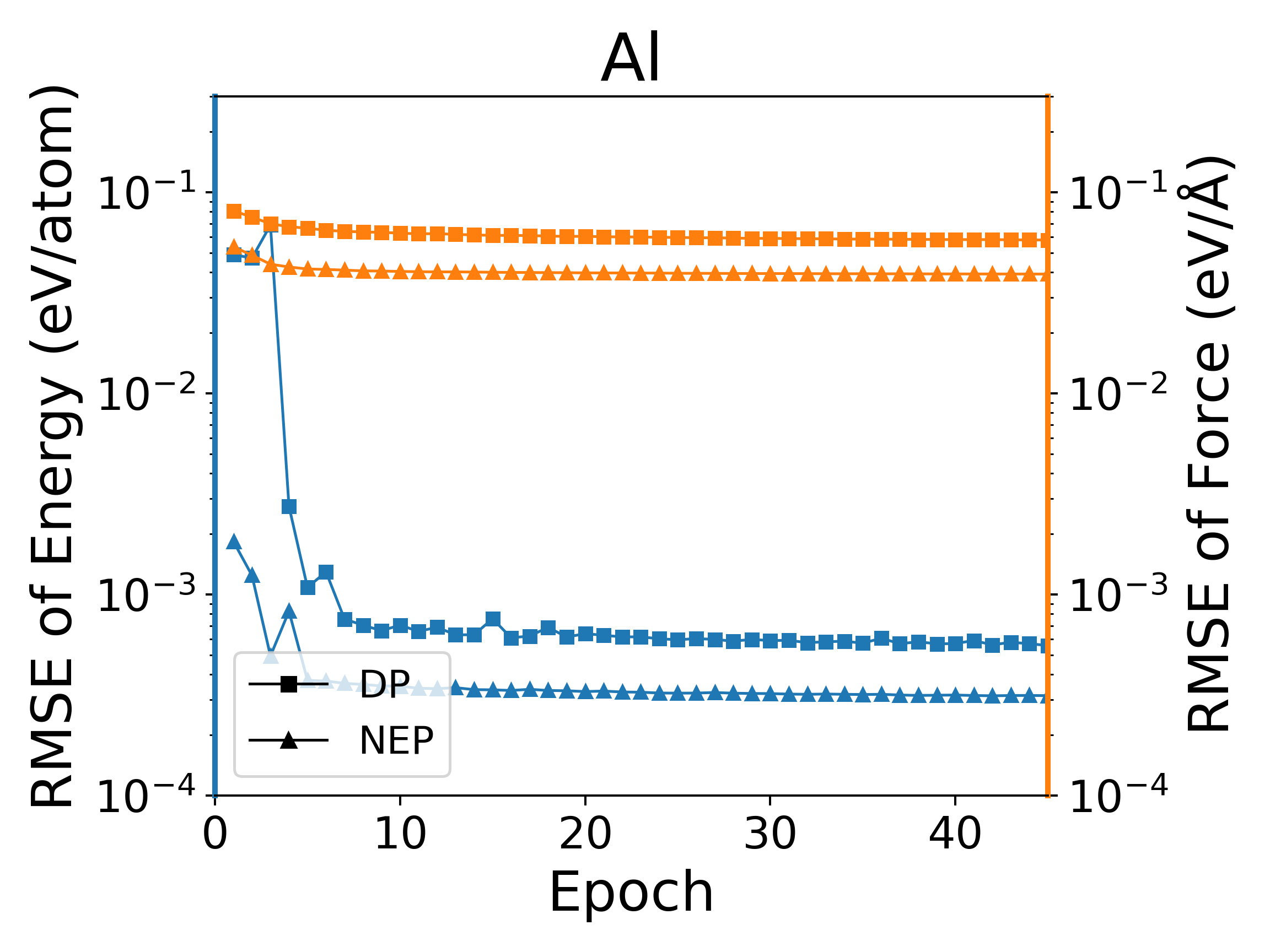
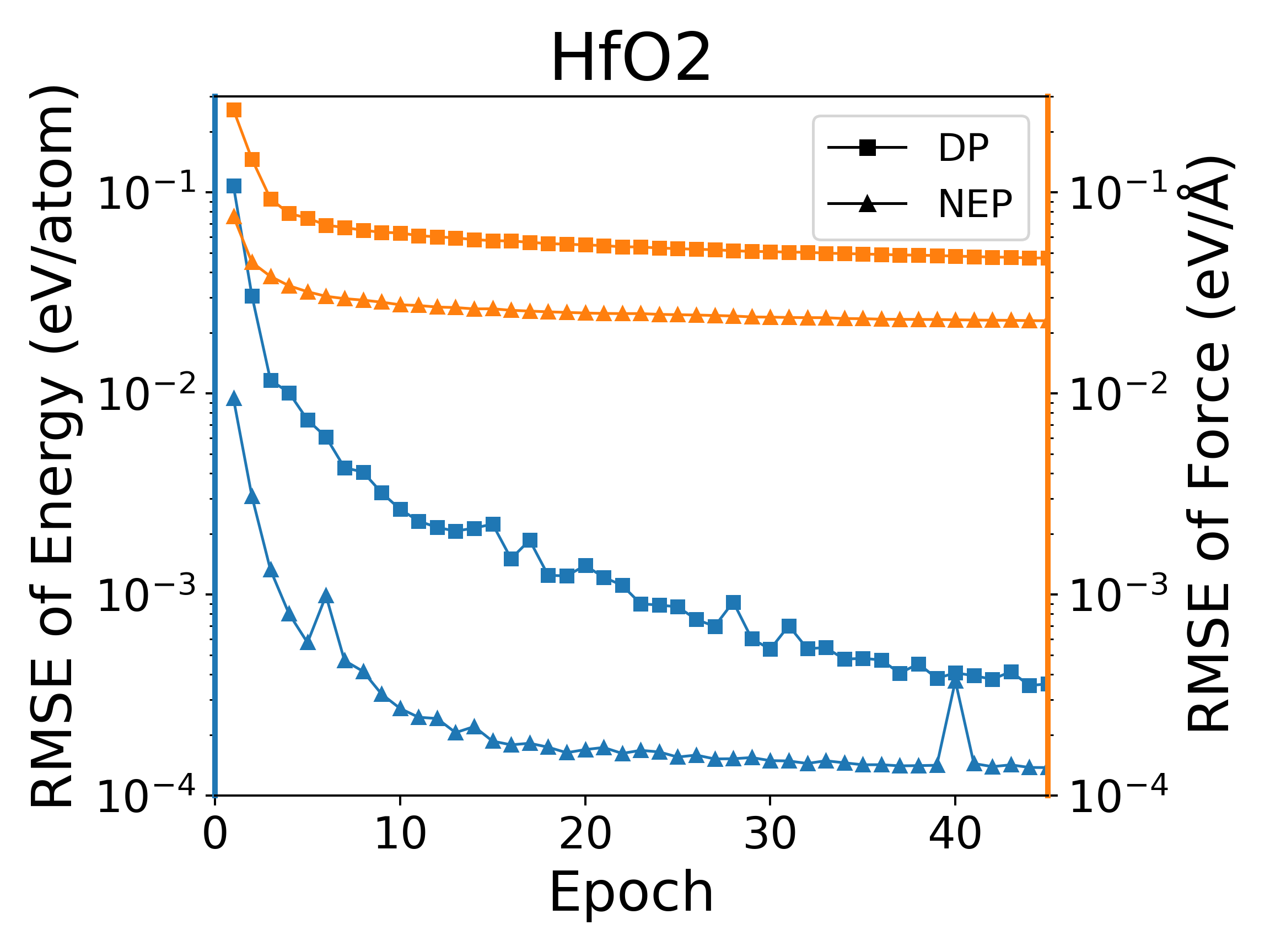
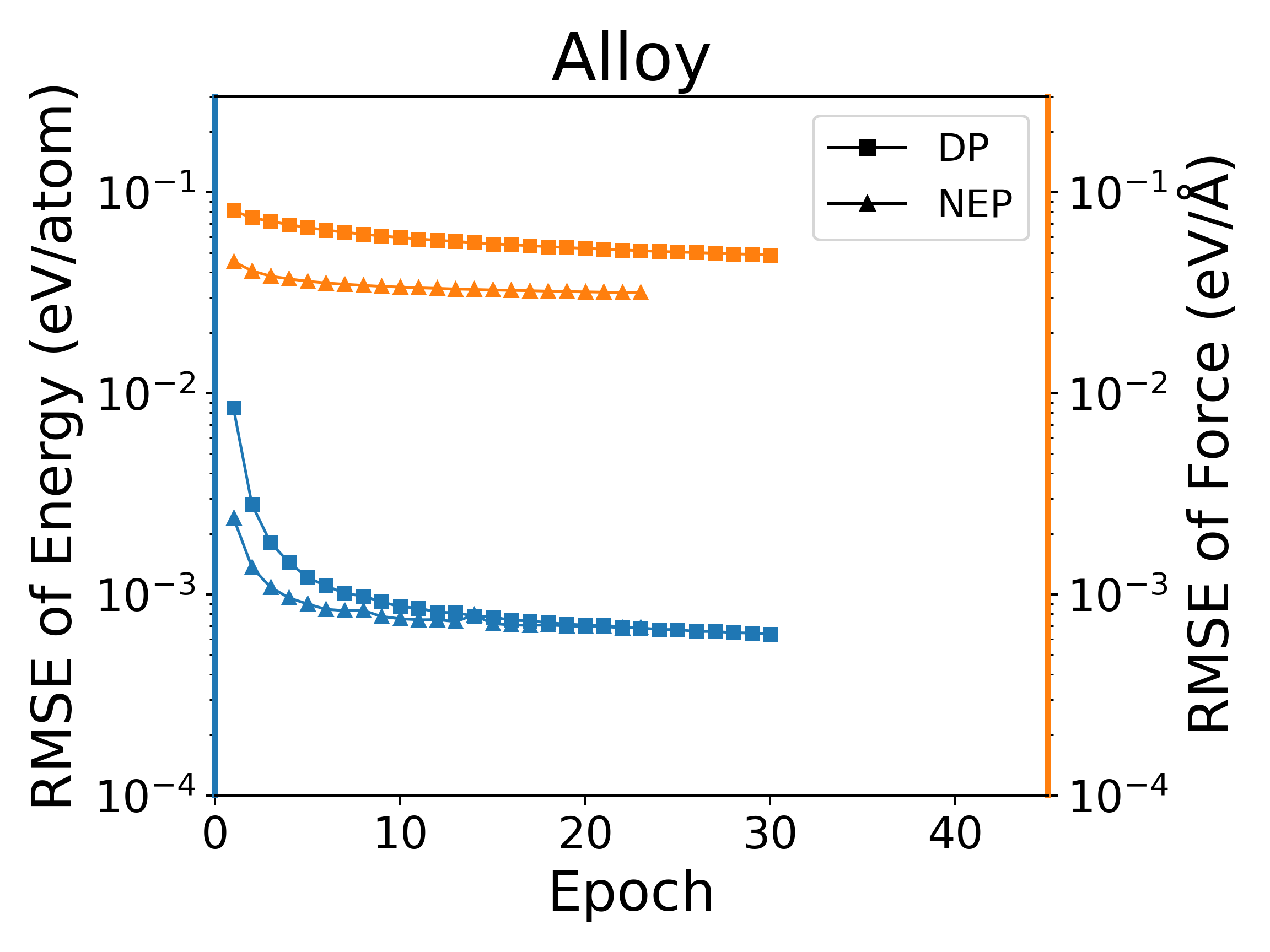
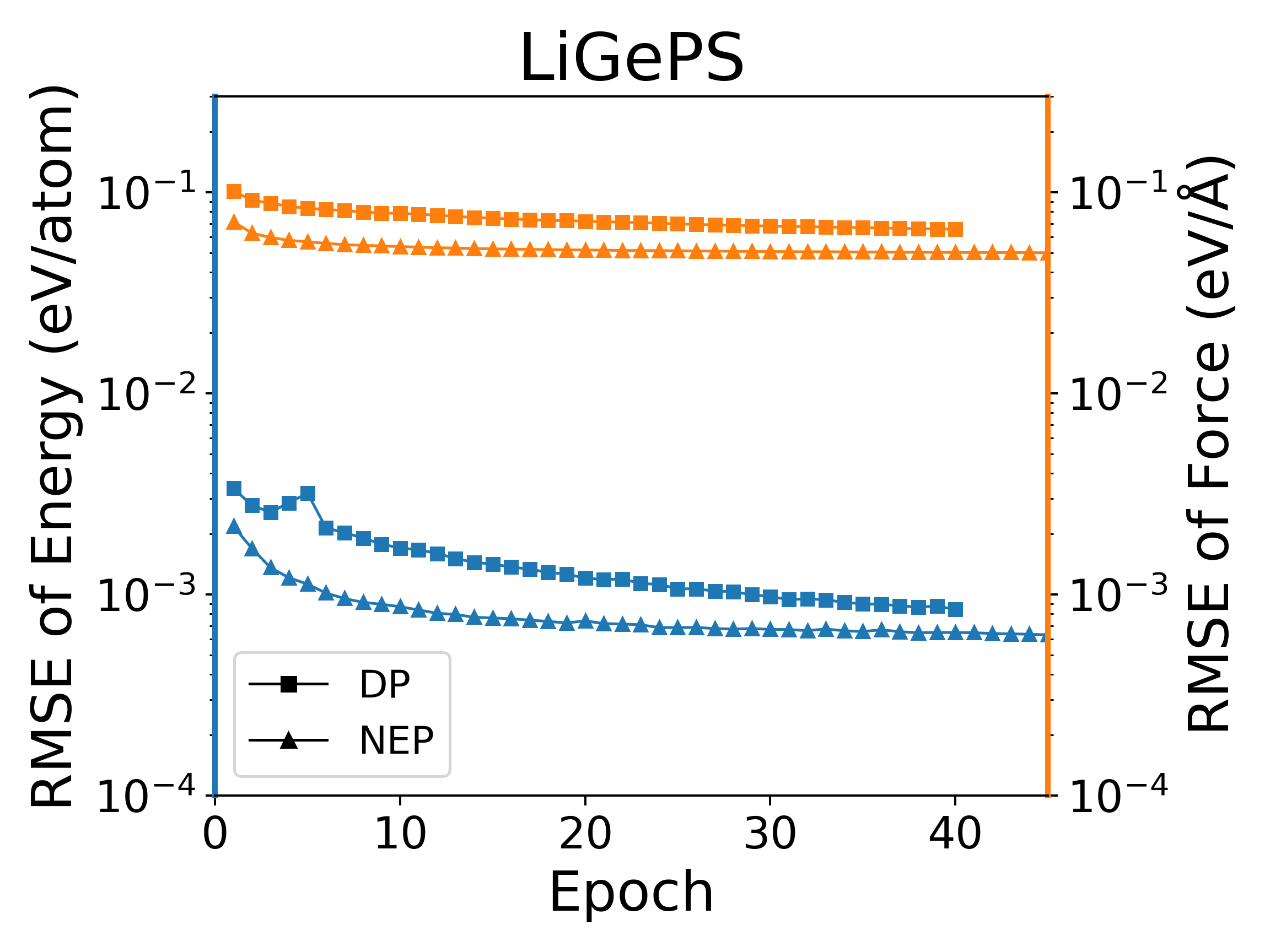
NEP和DP模型在LKF优化器下训练误差收敛情况
测试数据
测试数据与模型已经上传, 您可以访问我们的 百度云网盘下载 https://pan.baidu.com/s/1beFMBU1IehmNEpIQ9B8ybg?pwd=pwmt , 或者我们的开源数据集仓库。
关于lammps 接口的测试结果
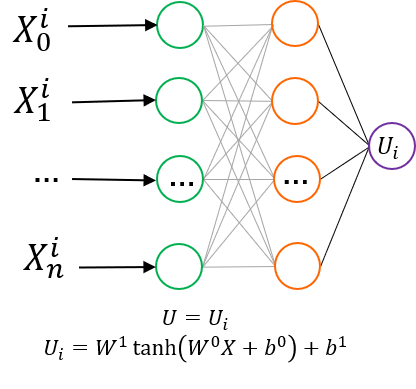
下图展示了 NEP 模型的 lammps CPU 和 GPU 接口在 3090*4 机器上做 NPT 系综 MD 模拟的速度。对于CPU 接口,速度正比与原子规模和CPU核数;对于GPU 接口, 速度正比与原子规模和GPU数量。
根据测试结果,我们建议如果您需要模拟的体系规模在 量级以下,建议您使用 CPU 接口即可。另外使用 GPU 接口时,建议您使用的 CPU 核数与 GPU 卡数相同。